
RAG(検索拡張生成)とは?仕組み・メリット・活用事例をわかりやすく解説
最終更新日: 2026年2月18日
RAGは、検索で根拠を取り出し、その情報を参照しながらLLMが回答を生成するアーキテクチャです。 この記事では、RAGの定義・仕組み・メリットと限界・活用事例・始め方まで、導入判断に必要なポイントを結論先出しで整理します。 RAGとは、「社内データを使いたいが、LLMがもっともらしい誤りを言うのが不安」という場面で検討されがちです。

要点まとめ
- RAGは、検索で根拠を取り出し、その情報を参照しながらLLMが回答を生成するアーキテクチャです。
- 効果は「検索品質」と「データ整備」に強く依存するため、運用設計(権限・更新・ログ)が成功の鍵になります。
- 知識の更新が頻繁な領域ではRAGが有利で、文章トーンや手順の型を固定したい場合はファインチューニングが有利になり得ます。
RAGとは?(Retrieval-Augmented Generation の基本概念)
RAGは「検索で関連文書を取り出し、その内容を参照して生成する」ことで、回答の根拠を外部データに持たせる方式です。
生成AI(LLM)は学習済みパラメータに知識を持ちますが、社内規程や最新仕様などは学習時点に存在しない場合があります。RAGは、その不足を検索で補う設計です。用語としてのRAGは、Lewis et al. (2020) が提案した Retrieval-Augmented Generation を指します。
用語メモ
- 検索(Retrieval): 質問に関連する文書を探して取り出す処理
- コンテキスト: LLMに渡す参照情報(根拠)で、回答の材料になる文章断片
- ベクトル検索: 文章を埋め込み(数値ベクトル)に変換し、意味の近さで検索する方法
関連理解として、まずは 生成AIとはを押さえ、次に AIエージェントとはで「検索やツールを使うAI」の全体像を見ると理解が早くなります。
RAGの仕組み(検索→コンテキスト付与→生成の3ステップ)
RAGは「検索 → 参照情報をプロンプトへ追加 → 生成」の3ステップで、生成の前提を“根拠付き”にします。
図解風に言うと、LLMにいきなり回答を作らせるのではなく、先に「材料(根拠)」を集めてから文章化させる流れです。これにより、社内ルールや製品仕様のような外部知識を回答へ織り込めます。
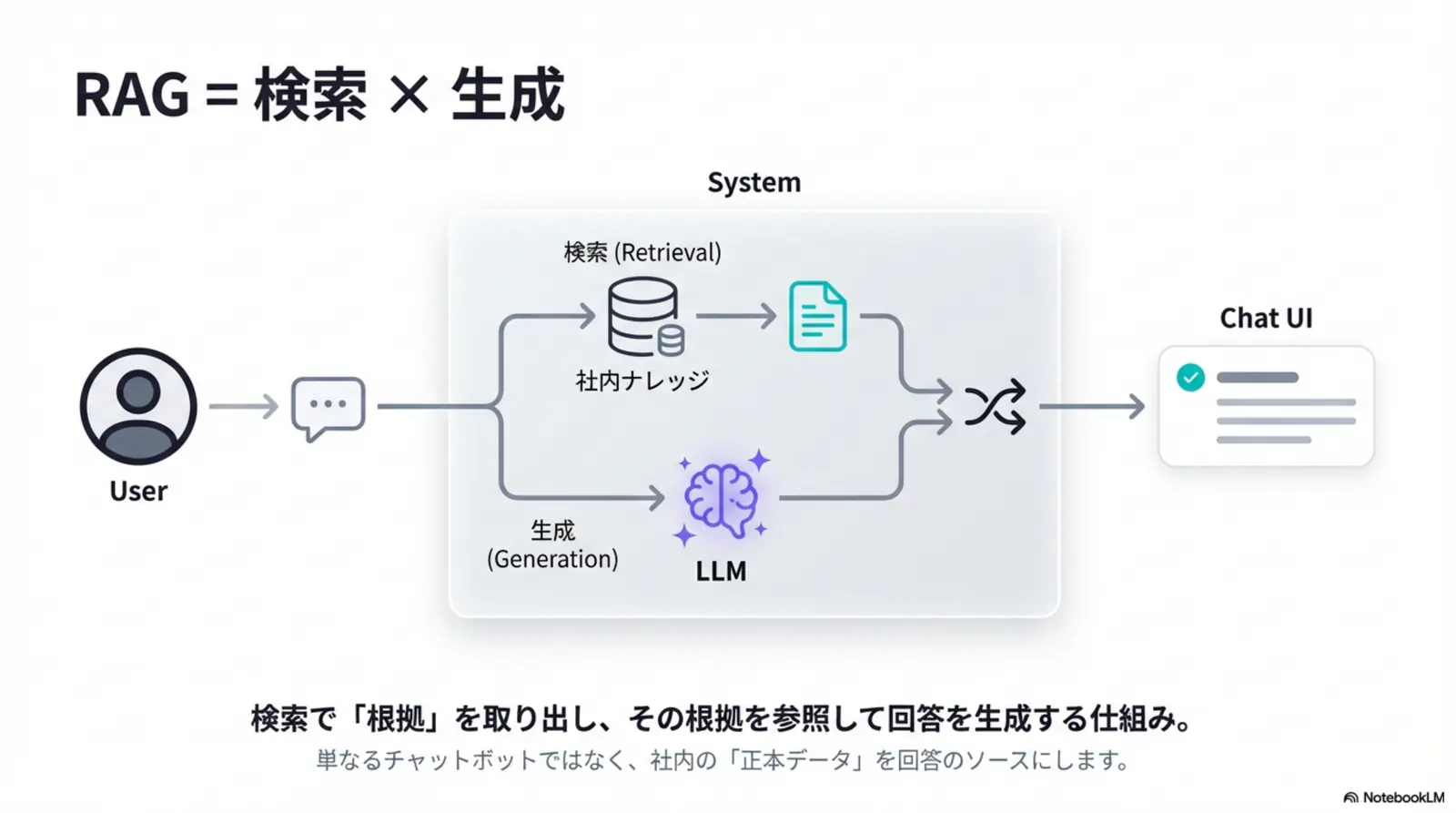
1. 検索(Retrieval)
質問に関連する文書を、ナレッジベース(社内規程・FAQ・Wikiなど)から探して取り出します。
例: ベクトル検索(意味検索)/ キーワード検索
2. コンテキスト付与(Augmentation)
取り出した文書の一部を「根拠」として、LLMに渡す入力(プロンプト)へ組み込みます。
例: チャンク(分割)/ 重要箇所の抽出 / 引用の整形
3. 生成(Generation)
LLMがコンテキストを参照しながら回答を生成します。必要に応じて参照元を提示します。
例: 回答 + 根拠(引用) + 次アクション
実装の勘所(よく出る用語)
- チャンク(chunk): 長い文書を検索しやすい単位に分割した断片。分割が粗すぎるとノイズが増え、細かすぎると文脈が欠けやすくなります。
- 埋め込み(embedding): 文章を意味を保った数値表現に変換する処理。ベクトル検索の前提になります。
- 再ランキング(reranking): 取得した候補文書を別モデルで並べ替え、より関連性の高い根拠を上位にする手法です。
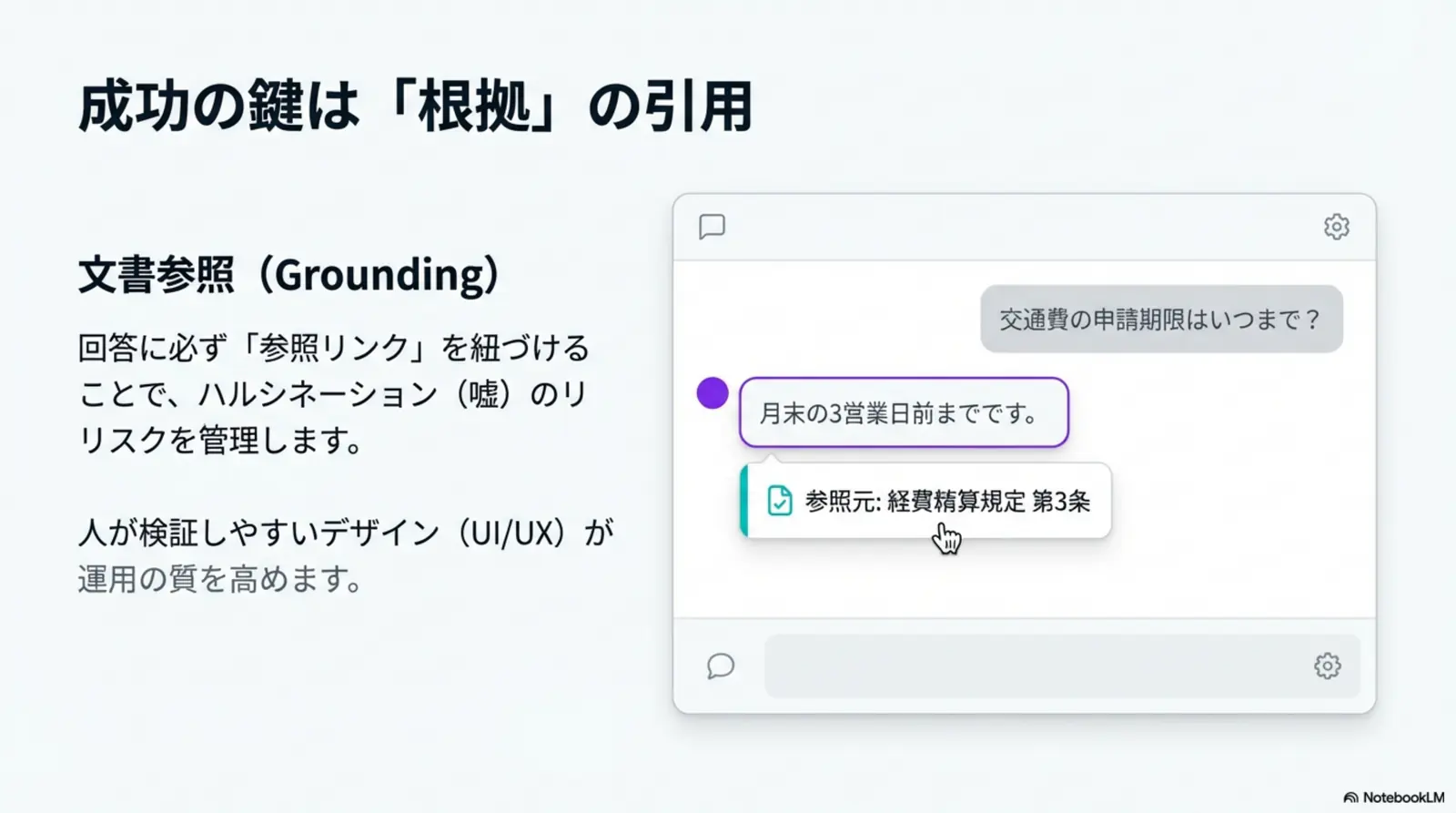
RAGが注目される背景(ハルシネーション対策、社内データ活用)
RAGが注目される理由は、(1) 根拠を参照させて誤りを減らす、(2) 社内データを安全に使う入口になる、の2点です。

ハルシネーション(もっともらしい誤り)対策
LLMは、回答の“形”は上手でも、根拠のない断定をしてしまうことがあります。RAGは検索で根拠を与え、回答の前提を固定しやすくします(ただし検索が外れると逆効果になることもあります)。
社内データ活用(学習させずに参照する)
ファイルをモデルに学習させず、必要なときに必要な範囲だけ参照させる運用ができます。権限管理やログ設計と組み合わせることで、企業利用での現実解になりやすいアプローチです。
企業側の進め方は 企業AI導入ガイドも参考になります。
RAGのメリットと限界(精度向上・最新情報対応 vs 構築コスト・検索精度依存)
RAGは「根拠で精度を上げる」点が強みですが、検索・データ整備・運用のコストが増えます。
メリット
- 精度(根拠)を上げやすい: 回答の土台となる文書を先に渡せるため、社内ルールや製品仕様など「根拠がある領域」で品質を安定させやすくなります。
- 最新情報に追従しやすい: モデルを再学習しなくても、ナレッジベースを更新すれば反映できます(ただし索引更新や権限設計は必要です)。
- 説明責任を持たせやすい: 参照文書(引用)を残せる設計にすると、レビューや監査、運用改善が進めやすくなります。
限界 / 注意点
- 検索品質に依存する: 検索で適切な文書が取れないと、生成品質も上がりません。データ整備(重複、古い版、表記揺れ)と評価が重要です。
- 構築・運用コストが増える: データ取り込み、分割(チャンク)、埋め込み、索引、権限制御、ログ分析などの運用が必要になります。
- 遅延・コストが増えやすい: 検索と生成を組み合わせるため、単純なチャットよりレイテンシとコストが増える傾向があります。
RAGの活用事例(社内FAQ、ナレッジベース、カスタマーサポート、法務文書検索)
RAGは「参照すべき資料がある業務」で効果が出やすく、問い合わせ対応・検索・下書き作成のような反復作業と相性が良いです。
社内FAQ / ヘルプデスク
人事・総務・情シスの問い合わせ一次回答を、社内規程や申請手順を根拠にしながら支援します。
ナレッジベース検索
Wiki、議事録、設計書などから「関連資料をまとめて提示」し、意思決定の初動を速くします。
カスタマーサポート
製品マニュアルや過去の回答を参照しながら、返信文の下書き・FAQ提案・担当者への引き継ぎを支援します。
法務・契約文書の検索
条項の探し当てや類似契約の参照を補助します(最終判断は必ず専門家が行う前提で運用します)。
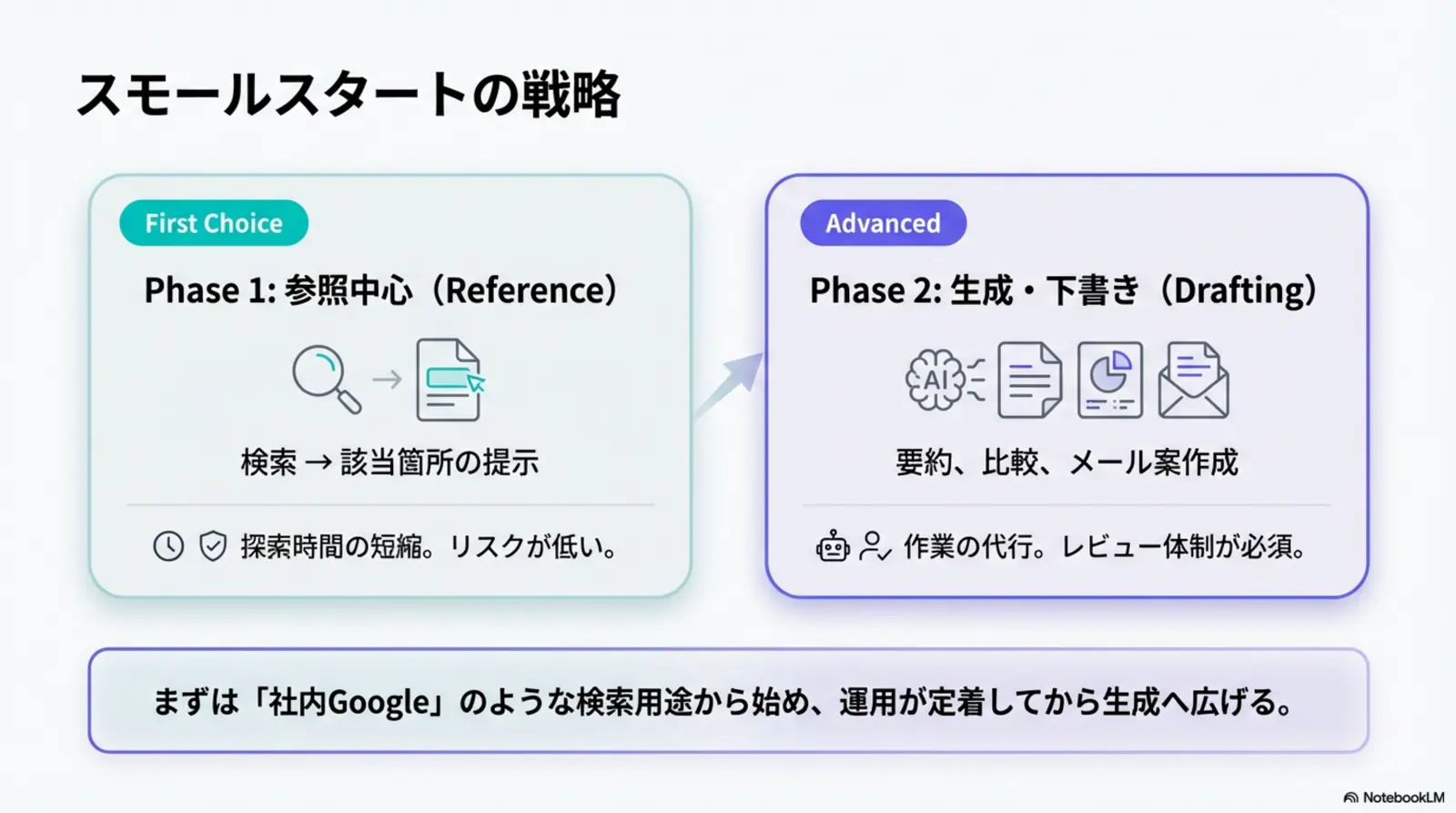
RAGを始めるには(主要フレームワーク: LangChain, LlamaIndex, Azure AI Search 等)
最初は「対象データ」「権限」「評価」を決め、検索の小さな成功(答えられる質問が増える)を積み上げるのが安全です。
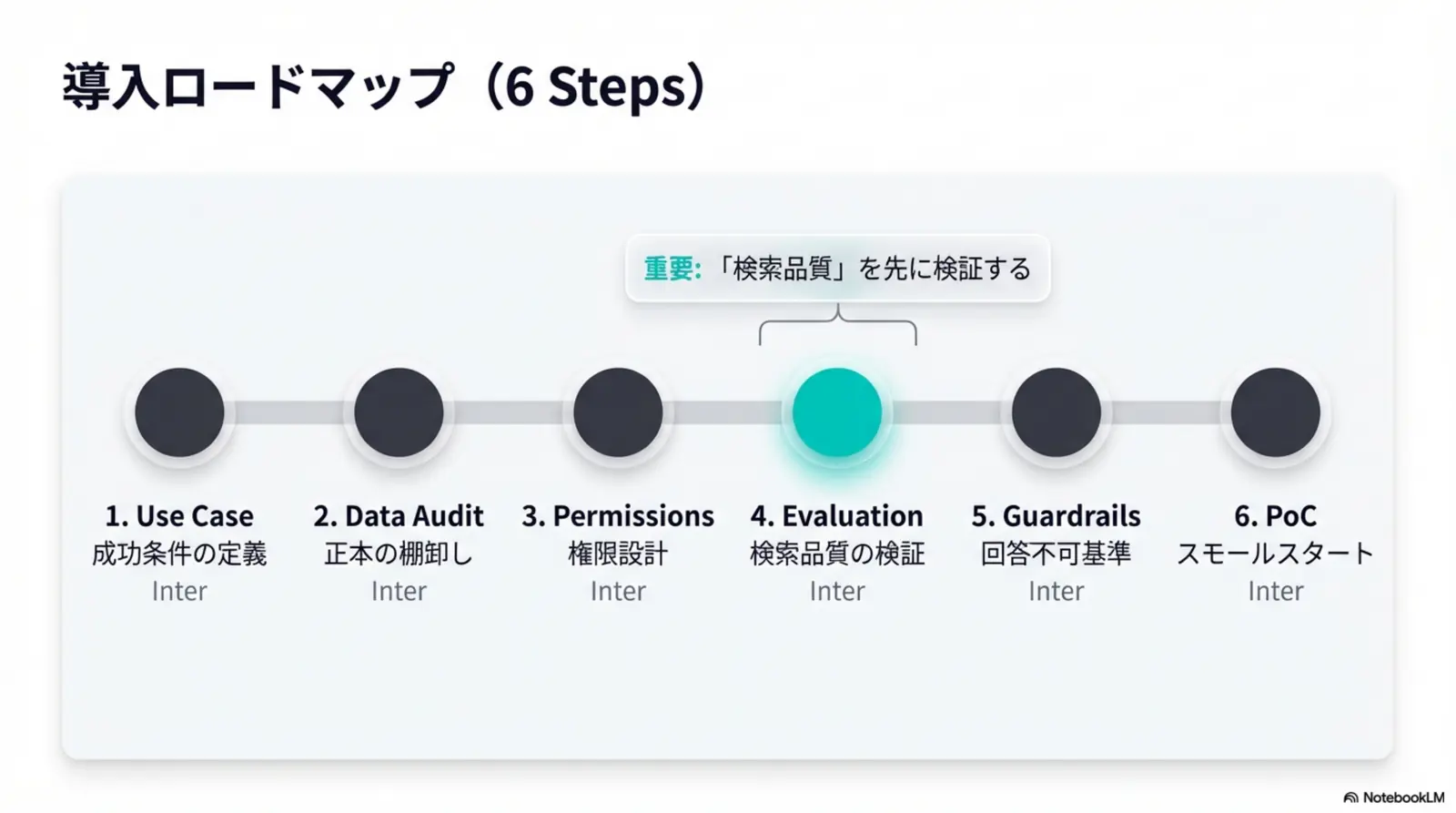
最小チェックリスト
- 対象データを決める(規程/FAQ/手順書など、根拠となる資料)
- アクセス権限を定義する(誰が何を検索できるか)
- 文書を整備する(重複排除、版管理、表記揺れの抑制)
- 検索方式を選ぶ(キーワード/ベクトル/ハイブリッド)
- 評価指標を決める(正答率、根拠一致、回答時間、一次解決率など)
実務でよく使う設計ポイント(2026年の定番)
- 検索はハイブリッドが基本: キーワード(BM25等)+ ベクトル検索を組み合わせ、必要なら再ランキング(reranking)で根拠の質を上げます。
- ベクトルDBは要件で選ぶ: まずはPostgres(pgvector)で小さく始め、スケールや運用要件でPinecone / Weaviate / Qdrant / Milvusなどを検討します。
- チャンキングは「見出し+意味のまとまり」重視: 固定長だけでなく、見出し/段落で分割し、必要に応じて重なり(overlap)を入れると文脈欠けが減ります。
- 評価は「検索」と「回答」を分ける: まず検索のRecall@k等で根拠取得を検証し、その上で回答の根拠一致(faithfulness)や再質問率など運用指標で改善します。
主要フレームワーク / 検索基盤
| 名称 | 概要 |
|---|---|
| LangChain | LLMアプリの部品(検索、プロンプト、ツール連携)を組み合わせてRAGを組むためのフレームワークです。 |
| LlamaIndex | ドキュメント取り込み(インデクシング)や検索、評価を中心に、RAGの基盤づくりを支援するフレームワークです。 |
| Azure AI Search | 検索基盤(インデックス、フィルタ、権限制御など)をマネージドで提供するサービスで、企業環境の検索実装に使われることがあります。 |
学習の進め方は 生成AIの学習ロードマップに沿って、まずは小さな実装と評価から始めるのがおすすめです。
RAGとファインチューニングの違い(使い分け判断基準)
知識を最新化したいならRAG、文章の型や判断基準を“学習”で固定したいならファインチューニング、という整理が基本です。
| 観点 | RAG | ファインチューニング |
|---|---|---|
| 知識の更新頻度 | 更新が頻繁でも、データ差し替えで追従しやすい | 再学習が必要になりやすい |
| 目的 | 根拠を参照して回答する(社内規程、仕様、FAQ) | 出力の癖や手順を学習する(トーン、分類、定型判断) |
| 失敗しやすい点 | 検索が外れると、根拠のない回答になる | データ品質が悪いと、誤った癖を学習してしまう |
| 運用の中心 | データ整備、検索評価、権限、ログ改善 | 学習データ設計、評価、再学習サイクル |
よくある質問(FAQ)
- Q. RAG(検索拡張生成)とは何ですか?
- A. RAG(Retrieval-Augmented Generation)は、ユーザーの質問に関連する情報を検索で取り出し、その情報(コンテキスト)を参照しながらLLMが回答を生成する仕組みです。
- Q. RAGはハルシネーション(もっともらしい誤り)対策になりますか?
- A. なります。ただし「検索で適切な根拠が取れる」ことが前提です。根拠が取得できない設計やデータ不足の状態では、誤りが減らない場合もあります。
- Q. RAGにはベクトル検索が必須ですか?
- A. 必須ではありません。キーワード検索などでもRAGは成立しますが、文章の意味に近い情報を取り出したい場合にベクトル検索(埋め込みによる類似検索)がよく使われます。
- Q. RAGとファインチューニングは何が違いますか?
- A. RAGは外部データを「検索して参照」し、ファインチューニングはモデルの重みを学習で更新します。頻繁に更新される知識はRAG、文章トーンや手順の型はファインチューニングが向くことが多いです。
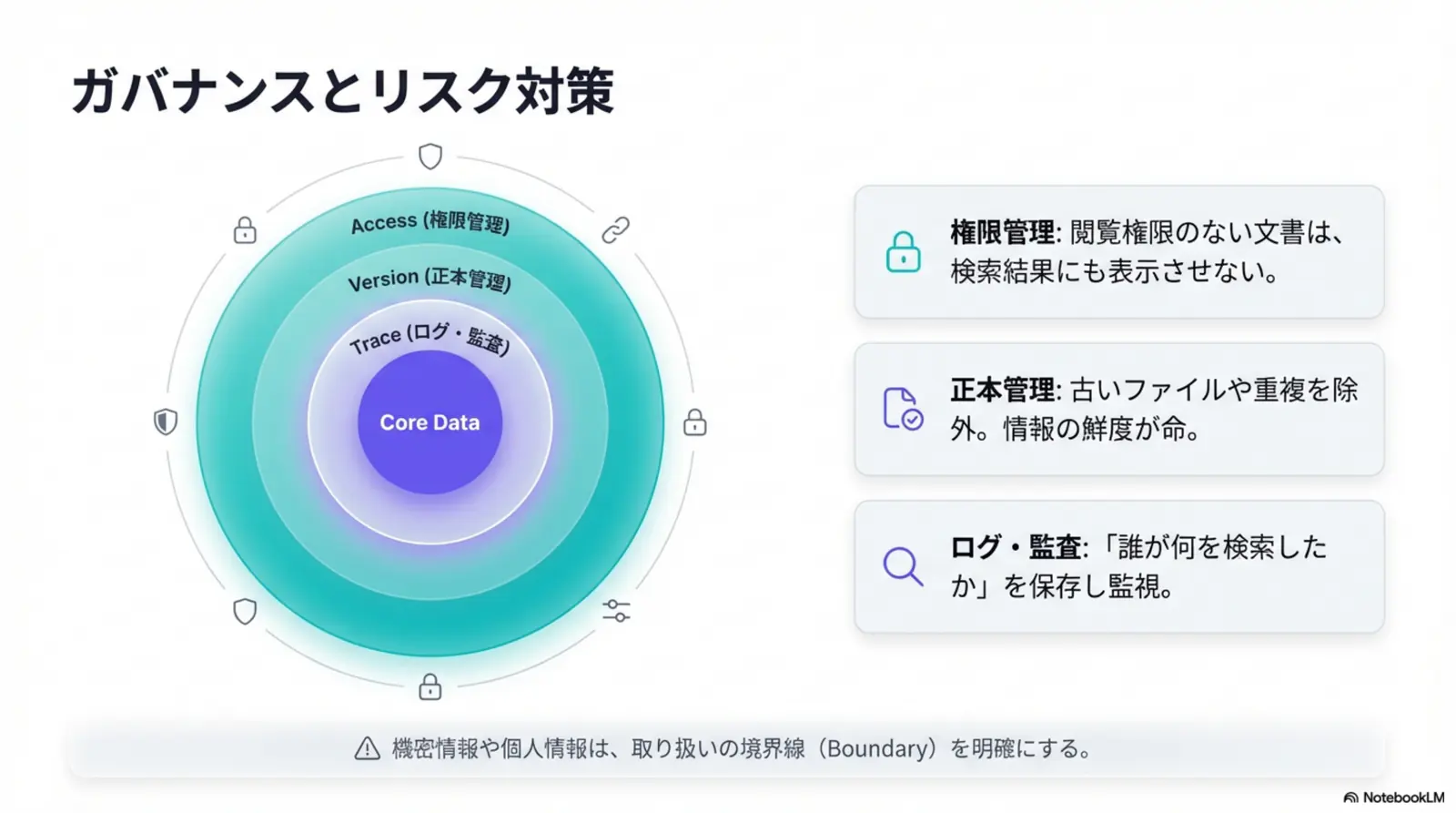
- Q. 社内データでRAGを作るときの注意点は?
- A. 権限管理(誰が何を参照できるか)、更新・削除の反映、ログ(検索クエリと参照文書)、個人情報/機密情報の取り扱いルールを先に決めることが重要です。
- Q. RAGはどんな業務で効果が出やすいですか?
- A. 社内規程や手順書、FAQ、製品ナレッジなど「参照すべき資料がある」業務で効果が出やすいです。問い合わせ一次対応やドキュメント検索のような反復業務と相性が良いです。
関連リンク
まとめ
- RAGは、検索で根拠を取り出し、その情報を参照しながらLLMが回答を生成するアーキテクチャです。
- 効果は「検索品質」と「データ整備」に強く依存するため、運用設計(権限・更新・ログ)が成功の鍵になります。
- 知識の更新が頻繁な領域ではRAGが有利で、文章トーンや手順の型を固定したい場合はファインチューニングが有利になり得ます。
AIリブートアカデミーで、AI活用の判断軸をキャリアに接続する

RAGは設計だけでなく、「何の価値を出すか」を言語化する思考OSと、運用・改善まで含めて考えると成果が出やすくなります。生成AI活用力だけで終わらせず、AIを鏡に自己理解・キャリアデザインを深め、100日間の伴走で仲間と一緒に実務アウトプットへ落とし込みたい方は、アカデミーの案内もご覧ください。
監修・更新日
監修: AI REBOOT編集部 / 最終更新日: 2026年2月18日
参考: Lewis et al. (2020) Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks(RAG原論文)